
本文授權轉載自 Austin Huang 未經同意請勿轉載、摘編
在上一篇文章「如何挑選適合的自動化模型?3大AI模型一次比較」中提到兩種方法及三種模型,我們在這篇文章會說明如何透過Python實做模型辨識功能及轉成結構化資料。
在方法部份我們選用多模態模型來進行單據辨識並依提示詞(Prompt)回覆我們所要的內容;而在模型部份我們選用辨識及推理能力表現較佳的Claude 3.5 Sonnet來實做(模型比較部份可參考上一篇文章)。
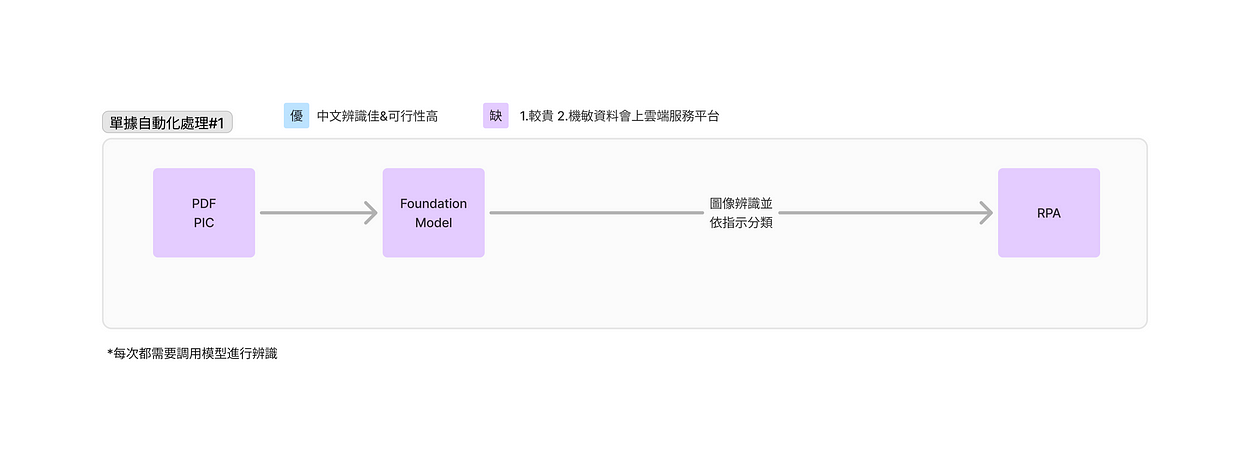
Python實做模型辨識5大步驟
要實做出單據處理自動化,我們可以參考以下流程架構:
- 蒐集各項單據檔案
- 透過RPA進行分類歸檔
- Python程式讀取分類後的檔案,將圖像或文字資料傳給模型進行辨識,模型則依照提示詞回覆所指示格式內容
- 每辨識完一張圖,用python程式寫入excel檔中
- 最後使用RPA將已結構化的excel檔內容自動填入指定系統中,完成自動化工作
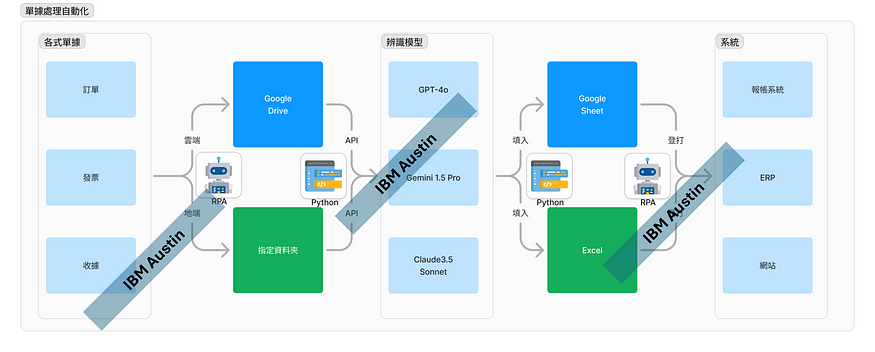
進得在使用Claude 3.5 Sonnet模型API前,需要先到官網註冊帳號、選擇付費方案(我是儲值10 USD來做測試使用)並建立一組API KEY才能調用模型。
*詳細API申請及使用方法可參考這篇文章 如何使用 Claude API
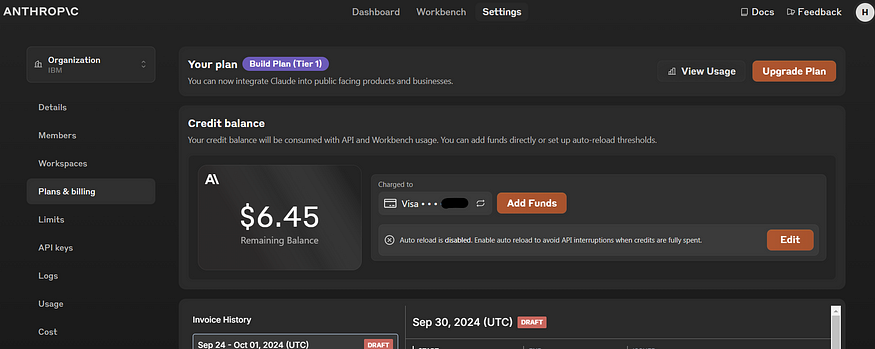
在使用神奇小卡💳付費儲值後,建立一個Workspace即可在Setting頁面看到Create Key的按鈕,點擊建立API Key後即可拿來使用。
接下來就是透過Python先串接API Key後在進行檔案辨識啦~ 由於我有一陣子沒碰python了😅…所以這邊就直接問Claude怎麼用python完成PDF讀檔以及串接Claude 3.5 Sonnet模型(懶人救星 AI寫程式法🤖)
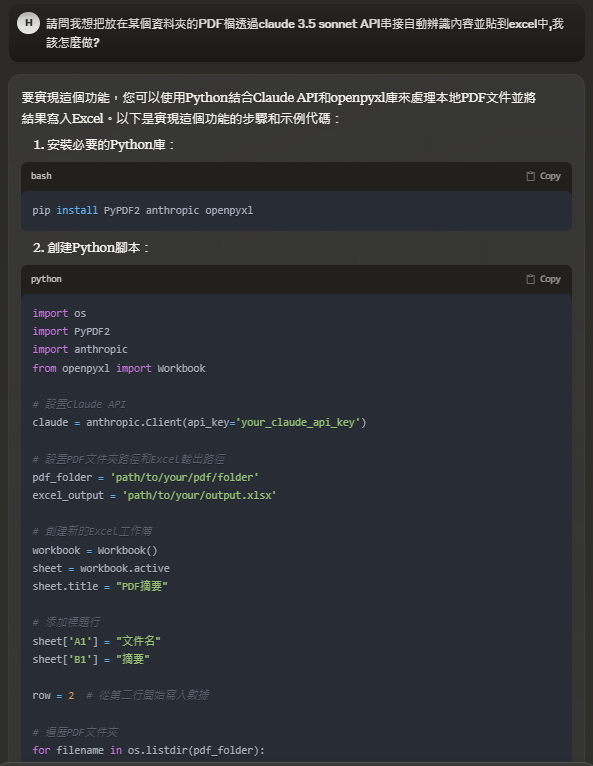
這邊由於涉及工作內容,我就不把完整程式貼上來了,大家可以試著問Claude怎麼寫,執行時如有錯誤也可以直接把error log貼上來問Claude怎麼解決,很可就可以完成這一段的程式編寫了💪
這邊比較麻煩的可能會是prompt的寫法,由於我們希望模型在辨識完圖像後能夠將我們要的內容轉為結構資料,故需要在prompt下這些提示詞,這邊是我針對履歷表辨識下的prompt給大家參考:
請依序提取這張圖片中的以下資訊:(姓名,信箱,電話,學歷,工作經歷,專長,性別,地址,摘要) 並以「 , 」做分格,須按照此格式及順序,不須回覆額外內容,如果無法判讀就回覆無法判讀,務必要回覆每個關鍵字的內容

在經由下prompt讓模型辨識資料後,我們再逐筆將每個檔案的資料寫入excel中,其中會發現模型回覆的內容有些並沒有按造我們要求的順序及內容準確回覆,而這部份也是在實做時最需要花時間做調整的地方。其中辨識的精準度主要會受模型能力及提示詞(prompt)所影響,所以大家可以多練習看下什麼prompt能夠得到最準確的辨識回覆。
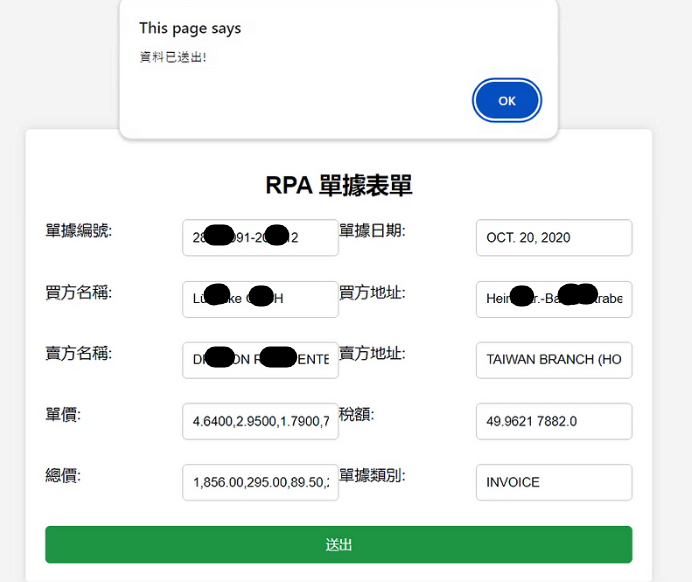
最後我們再透過RPA將已結構化的資料excel檔逐筆填入系統中,即可完成單據辨識自動化的流程囉🤩
專欄作者簡介:Austin Huang
現任台灣IBM Data&AI售前顧問,專司企業流程自動化解決方案。曾任職於KPMG擔任數位轉型顧問,擅長RPA開發、資料視覺化及流程自動化工具導入,並具有製造、金融領域幕僚及業務經驗。
先行智庫為台灣管理顧問公司,服務內容包含整合行銷官網服務、企業內訓、顧問諮詢以及數據解決方案,了解更多企業服務內容:https://kscthinktank.com.tw/digital-marketing/